If it runs pytorch at speed without hand holding I would probably get one.
If it runs tinygrad at speed(a lower bar developmentally) I might get one.
Is there a model benchmarking site where you can select varying degrees of models by source code and see how they perform on different hardware. It would assist people to evaluate whether or not a specific piece of hardware is good for the jobs that they want it to do.
> Is there a model benchmarking site where you can select varying degrees of models by source code and see how they perform on different hardware. It would assist people to evaluate whether or not a specific piece of hardware is good for the jobs that they want it to do.
Not that I'm aware of (at least based on real benchmarks), but it's something I've been noodling about building, together with with some other associated data that can be helpful when wanting to select a model. Glad to hear I'm not the only one wanting it :)
100% chance its chewing through at least 50% more power to achieve the result.
Infact based on their TDP guidance, it goes up to 120w, which is more than double M4. But we don't know what the configuration was for this benchmark. We also don't have great numbers for M4's power consumption either.
Then you throw in the fact 120w TDP from AMD is not actually a power consumption figure... and it's all made up.
M4 Max is the most comparable to Strix Halo and while Apple does not appear to give an official power consumption, there are plenty of anecdotal reports of it using over 100W under load. For example:
Not to mention what's the performance like on battery vs. plugged in. If I have to stay tethered to the wall in order to achieve the rated performance then it's not really an apples-to-apples comparison unless you only ever use your laptop at a desk (which is probably most people, honestly).
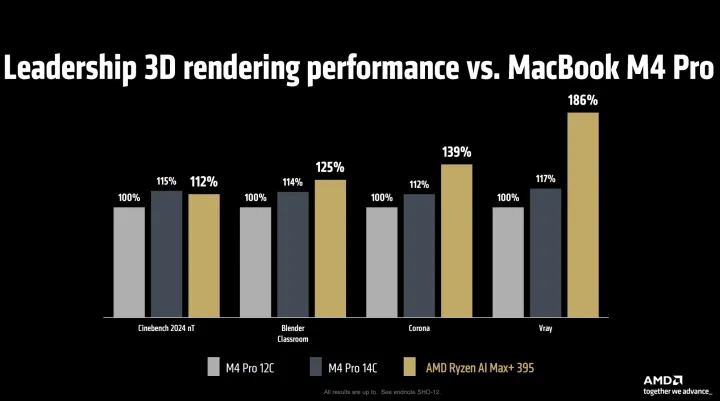
What is the graph supposed to measure, actually? Renders are usually measured in seconds, so high=worse, but then clearly they highlight it as they're better, so it's the second-difference as a percentage or something?
Why can't companies just include absolute numbers in their comparisons...
It's first party marketing so always orienting the scale towards "higher=better=ours" and measuring via "whatever measurement gave the best numbers to present". They could give all the information in the world and I'd still wait and see what 3rd party reviews say the performance actually is rather than look into the 1st party number.
They should but it’s not favourable. In their presentation they specifically said it outperforms the binned M4 Pro and is on par with the unbinned M4 Pro.
It would be behind the M4 Max. It’s also over double the wattage of the M4 Pro to achieve these numbers.
Even M4 Pro is a big step up. M4 max is pretty expensive and I suspect AMD is targetting a lower price point, not that any prices were mentioned today.
256 bits * DDR5-8533 is a pretty big step up from any other x86-64 laptop or SFF and should be a pretty huge help for anything graphics or bandwidth intensive, like LLMs.
I'd expect laptops with this thing will be available at closer to the Pro (~$2k) than the Max (~$3k). I see a laptop with the 375 for ~$1700 right now, which is more comparable to the 10-core M4. Or in the minipc space, the 370 is ~$1k, which would again be comparable to a 10-core M4 mac mini.
I think the AI appears on any SKU with enough TOPS for copilot+ (they released some 200 SKUs that are just Ryzen 5/7, no AI)
Max is the segment number i.e. it's "Ryzen 11" (the other 300 series SKUs they announced are Ryzen AI [5|7] 3xx). Weirdly though there are no Ryzen 9s so maybe it's really just a rebrand of 9.
The Pro just means it has management and security features for enterprise customers.
Yeah but they had pretty meagre memory bandwidth until now, aside from the parts they made exclusively for Xbox and Playstation. AMD didn't seem to be interested in bringing fast unified memory to real computers until Apple did it. Now they need to double up the bus again to make an M4 Max-alike...
In part because it's an odd compromise. With the exception of LLM's which are a decent development... there wasn't a lot of need to high memory, but moderate GPU compute parts. You'd either have a lot of memory and a CPU, or a lot of memory and a beefy GPU.
It isn't what the market wanted, and by market I mean OEMs, because I'm sure consumers would have loved it.
The OEMs buying APUs to use in laptops and SFF desktops were more interested in cutting costs than boosting graphics performance. Users who want better 3D performance can buy a higher end laptop with a discrete GPU and juicier profit margin.
True, but apple's the benchmark in this space and have managed thin laptops with good battery life and decent (but not class leading) GPU performance.
Doubling the memory width (and tripling the bandwidth) helped Apple's GPU performance substantially and should do the same for AMD. Which means that a larger fraction of the laptop market should consider it "good enough" and still have a reasonable TDP to avoid the 2" think laptop that last for less than an hour on battery while sounding like a hair dryer.
Those agreements would be >15 years old at this point, I doubt AMD would agree to sandbag their entire APU lineup going forward just to make the base model PS4 and Xbone look good, and I especially doubt that they would do that again with the PS5 and Xbox Series when they actually had money and room to negotiate. Likewise, it doesn't make sense as a restriction Microsoft or Sony would impose: the console business is one of convenience, not power. They aren't trying to beat PCs and they don't care if PCs are a better deal. They care if they can get you to buy a box that locks you into their DRM scheme.
Furthermore, during the chip shortages of the last few years, AMD was actually selling broken PS5 silicon for use as a normal Windows PC[0]. If there were restrictions on selling APUs above a certain performance level, then this PC wouldn't exist.
Historically PC OEMs cared about price more than graphics performance so that's what they got. If you look at mobile SoCs or the eDRAM-equipped SKUs Intel made for Apple you see more emphasis on memory & graphics performance similar to consoles.
Intel's Knights series of chips (a.k.a. Xeon Phi, a.k.a. Larabee) for servers shipped 8gb of 320gb/s on package memory in 2012: https://en.wikipedia.org/wiki/Xeon_Phi
It "just" doubled the memory bus width from 128 to 256 bit and cranked up the interface clock speed. I wonder what it means for the infinity fabric. Is it going to run at ~4GHz to keep up?
It uses LPDDR5X-8000, with a 256-bit memory interface (double in comparison with standard desktops).
8 GHz x 32 bytes = 256 GB/s
This has been known for a long time.
What annoys me is that AMD does not say whether the Zen 5 cores of Strix Halo have full vector processing pipelines, like Granite Ridge and Fire Range, or they have the narrow pipelines of Strix Point and Krackan Point.
Various leaks have claimed that some products would ship with DDR5-8533 which is 266GB/sec. I wouldn't be surprised if a range of frequencies ship with the 1st gen devices.
Maybe even a SFF sized motherboard that allows CUDIMMs, which is a nice fit since each CUDIMM is 128 bits wide.
> If AMD keeps with tradition, which we fully expect, we will see these monstrous APU chips come to desktop PCs in the future.
How far in the future? I don't need another laptop, but would be nice to have a box to run local llms on. If these things can run LLMs at a decent clip then this would be sort of a "shut up and take my money" situation.
I hope the LLM benchmarks announced were reasonable and not something gross like using a model that doesn't swap on the Strix Halo, but does on a 4090.
HP announced a HP Z2 mini g1a, which is bigger than a NUC, but I believe still considered a SFF:
After digging it looks like 70B Q4 requires 35GB or so. So yes the AMD comparison is a strix halo not swapping vs a 4090 that is swapping. Seems kinda misleading, but is a real advantage for larger models.
Sure, but the previous iterations (like Strix in the non-halo form) and similar AMD laptop chips are popular with numerous SFFs from the likes of ASUS, ASRock, Gigabyte, Beelink, Minisforum, GMKtex, Lenovo, and many others.
I've heard similar rumors of similar SFFs from framework, system76, and similar VARs.
The Strix Halo does seem pretty compelling for those that want less volume, power, and money than a discrete GPU. I'd love a small SFF with either 128GB ram (some parts will have the ram in the package)) or two CUDIMM slots.
Generally SFFs use laptop parts, but tend to be out a few months later than the equivalent laptops.
The strix halo announce was pretty much exactly what was leaked.
However one big surprise was that the Halo 395 chip runs Llama 3.1 70B-Q4 2.2x times faster than a RTX 4090 24GB. Anyone have any details? The slide mentions seeing AMD endnote SHO-14 for details.
It mentioned Q4, but after searching around a bit looks like 70B-Q4 need 35GB or so. So strix halo is 2.2x faster than a 4090 when it's paging to system ram.
sure. But that's kind of the point. A 4090 with 24GB is going to cost more than one of these strix halo mini PCs with 64GB to 128GB. You're going to be able to run larger models on it without thrashing around between VRAM and DRAM. Will it run as fast as a model that could fit entirely on that 4090? No way, but it will be able to run larger models at fairly decent speed for home use.
I'm optimistic that it won't be a big issue. After all if 256 bit wide memory helped a wide range of application it would have been added earlier. After all xbox and playstation have had similar for 2 generations so far.
The bandwidth should mostly help the GPU performance for games or LLMs, but not random desktop apps.
Usually, this is all about memory latency. Until the game devs are aware of this latency issue, games should be ok... but it means you need more control on CPU machine code execution, in other words, you need to ge closer to the bare metal.
100fps is 10ms for a frame (we now know 60pfs is not enough, fps must never drop below 75-80fps, but I would really target 100+ fps)
"All of the AI Max chips have a 55W base TDP, but also a configurable TDP that ranges from 45 to 120W to unleash more horsepower in designs that can handle the thermal output."
Seems unlikely, at least for any normal use case. PCIe 5.0 (the current standard that is widely shipping) has 16GB/sec in each direction (32GB/sec total) with a x4 connection.
Doubly so that for the last decade or so memory sizes haven't increases. Seems like the vast majority of machines these days are 8-16GB ram and have a max of 64GB ram unless you are buying workstation parts.
How many times a second do you need to load 100% of ram from storage?
The quoted tdps seem to be for CPU+GPU combined and these SKUs have huge increases in GPU size (40 CUs up from a max of 16 last gen). The M4 Pro and M4 Max fall into the same tdp range.
That's for both CPU, supposedly no-longer puny iGPU and the NPU. You'll get ≥80% real-world throughput for about half the power budget which is can easily be cooled in a 14" laptop that's thin for a gaming laptop without shattering your eardrums. I'll grant that you'll have to pick between acceptable acoustics, thermal throttling, or form factor when you go beyond 60W continuous heat output.
{kind=link}
{kind=link}
If it runs tinygrad at speed(a lower bar developmentally) I might get one.
Is there a model benchmarking site where you can select varying degrees of models by source code and see how they perform on different hardware. It would assist people to evaluate whether or not a specific piece of hardware is good for the jobs that they want it to do.